

The Evolution of Data Processing: From Batch to Real-Time
Historical Context
Initially, data processing was done in batch mode, where data was collected over a period (e.g., daily sales) and processed in bulk.
Mainframes were designed for large-scale batch jobs, running them overnight or during low-traffic hours.
Example: A retail store collects daily sales data and processes it at midnight to generate reports for the next day.
Limitations of Batch Processing
High Latency: Results are delayed because data is processed only after a significant time gap.
Inefficiency for real-time scenarios: If fraudulent transactions are detected only after a day, it may be too late to act.
Emergence of Stream Processing
Processes data as it arrives, enabling real-time insights.
Example: A credit card fraud detection system flags suspicious transactions instantly, allowing immediate action.
What is Spark Streaming?
An extension of Apache Spark for real-time data processing.
Splits incoming data streams into micro-batches and processes them using Spark’s distributed computing power.
How Spark Streaming Extends Apache Spark
Spark processes batch data; Spark Streaming enables near real-time processing by treating data streams as small batches.
Uses standard Spark operations like map(), filter(), and reduce().
Key Features
Real-time Processing: Provides immediate insights.
Scalability: Handles high-velocity data streams.
Fault Tolerance: Ensures data reliability.
Integration: Works with Spark SQL, MLlib, and Kafka.
Unified API: Same API for batch and streaming.
Use Cases
Real-time Analytics: Updating dashboards with live sales metrics.
Fraud Detection: Catching suspicious transactions instantly.
Stock Market Analysis: Streaming stock prices for real-time trading.
Advertising: Displaying ads based on live user behavior.
IoT Monitoring: Analyzing sensor data to predict failures.
Micro-Batch Architecture, DStreams, and Transformations
Micro-Batch Architecture
Data is split into small time-based batches and processed sequentially.
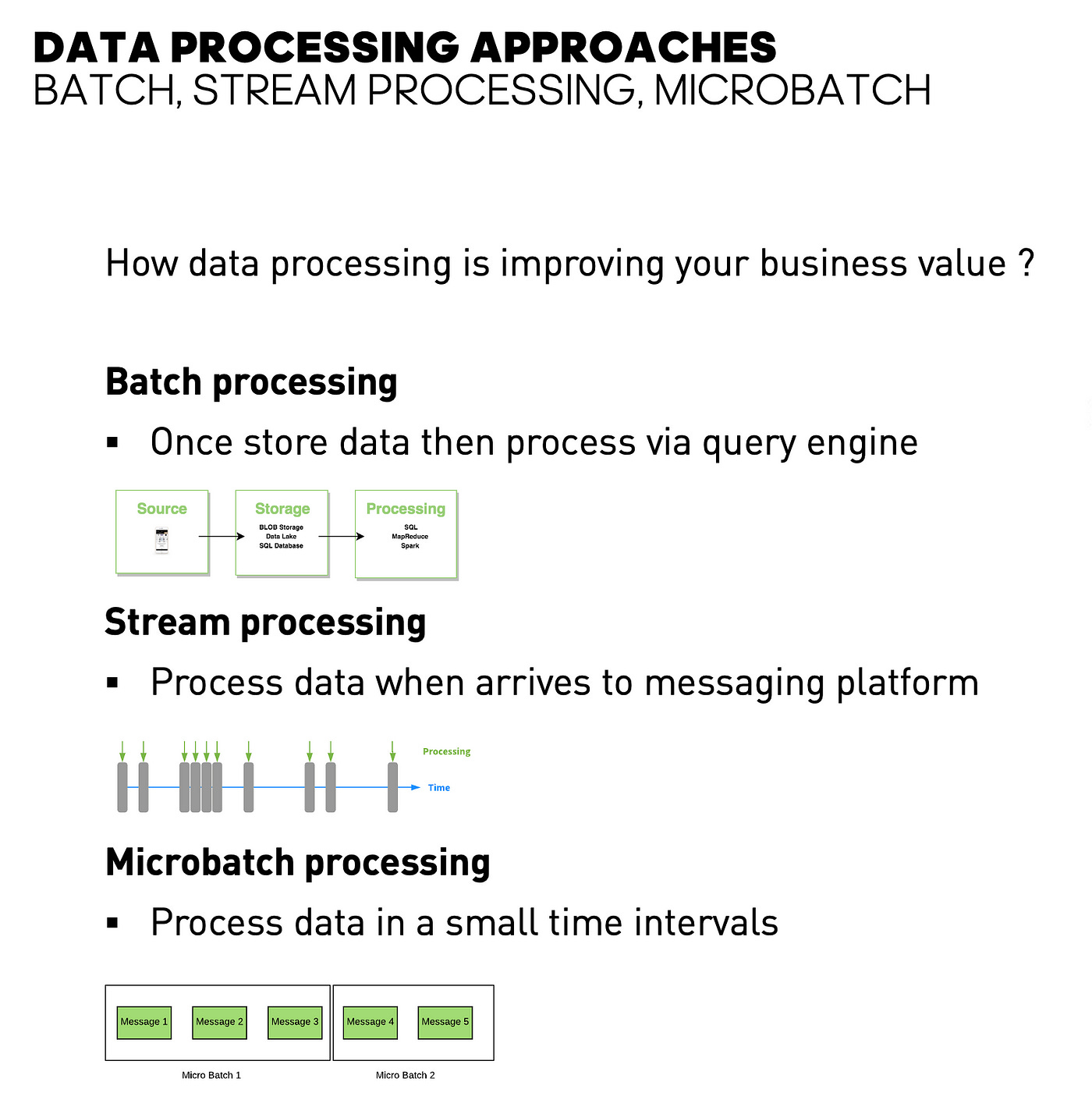
A data processing model where incoming data is divided into small, time-based batches and processed at regular intervals.
Unlike traditional batch processing (where large datasets are processed periodically), micro-batching processes data as it arrives, but in small chunks.
This approach is widely used in streaming frameworks like Apache Spark Streaming, where data is processed in short time windows (e.g., every 5 seconds).
How to Achieve Micro-Batch Processing?
Ingest Data Continuously
Data is received from sources like Kafka, HDFS, or socket streams.
Buffer Data into Micro-Batches
The framework groups incoming data based on a fixed time interval (e.g., 5 seconds).
Process Each Micro-Batch in Parallel
The batched data is processed using distributed computing techniques.
Store or Forward Results
The processed data is either stored in a database or published to another system (e.g., dashboards, Kafka).
How Does Spark Enable Micro-Batching?
Spark Streaming achieves micro-batching by converting data streams into Discretized Streams (DStreams), where each micro-batch is an RDD (Resilient Distributed Dataset).
Spark uses the Spark StreamingContext to control the batch interval.
It integrates with Kafka, Flume, and other data sources to pull data continuously.
Uses parallel execution on a cluster for high-speed processing.
How Does Micro-Batching Help in Streaming Solutions?
Balances Latency and Throughput
Unlike event-by-event processing, micro-batching reduces system overhead while still providing near real-time insights.
Fault Tolerance
Micro-batches can be recomputed in case of failure using checkpointing and write-ahead logs.
Efficient Resource Utilization
Data is distributed across executors, enabling efficient parallel processing.
Seamless Integration with Batch Systems
The same Spark transformations work for both batch and micro-batch streaming.
Use Case
Broker needs to process live stock prices and detect anomalies.
Data from a stock exchange (via Kafka) is micro-batched every second and analyzed.
The system identifies sudden spikes or drops and triggers alerts.
Example
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Initialize Spark Context and Streaming Context (Micro-batch interval: 5 sec)
sc = SparkContext("local[2]", "StockPriceMonitoring")
ssc = StreamingContext(sc, 5)
# Read stock price data from a socket stream
stock_data = ssc.socketTextStream("localhost", 9999)
# Process micro-batches: Extract stock symbols and prices
parsed_data = stock_data.map(lambda line: line.split(",")).map(lambda x: (x[0], float(x[1])))
# Detect high price variations (e.g., more than 5% change)
def detect_spike(rdd):
for record in rdd.collect():
stock, price = record
if price > 1000: # Example threshold
print(f"ALERT! {stock} price is too high: ${price}")
parsed_data.foreachRDD(lambda rdd: detect_spike(rdd))
# Start streaming
ssc.start()
ssc.awaitTermination()This implementation:
Reads live stock prices from a socket.
Processes data in 5-second micro-batches.
Identifies anomalies and prints alerts.
Example: A conveyor belt where each batch represents a time window of incoming data.
DStreams
A DStream is a sequence of RDDs, each representing a micro-batch.
Example: A stream of logs from a web server.
Transformations on DStreams
Similar to RDD transformations, but applied to each micro-batch.
Example: Converting a temperature stream from Celsius to Fahrenheit using map().
from pyspark.streaming import StreamingContext
from pyspark import SparkContext
sc = SparkContext("local[2]", "TemperatureConversion")
ssc = StreamingContext(sc, 5) # 5-second micro-batches
temp_stream = ssc.socketTextStream("localhost", 9999)
fahrenheit_stream = temp_stream.map(lambda c: (c * 9/5) + 32)
fahrenheit_stream.pprint()
ssc.start()
ssc.awaitTermination()Micro-Batch Architecture, DStreams, and the Role of the Driver
How Spark Streaming Works
The incoming data stream is buffered into small micro-batches.
Each micro-batch is processed using standard Spark jobs.
Smaller batches reduce latency but increase system overhead.
Batch vs. Stream Processing
Batch Processing: High latency, suitable for historical analysis.
Stream Processing: Low latency, suitable for real-time actions.
DStreams: The Foundation of Spark Streaming
DStreams
Sequence of RDDs representing continuous data.
Can be transformed using Spark operations (map(), filter(), etc.).
log_stream = ssc.textFileStream("hdfs://path/to/logs")
error_logs = log_stream.filter(lambda line: "ERROR" in line)
error_logs.pprint()Driver Program: Orchestrating the Streaming Application
Responsibilities of the Driver
Creates the StreamingContext.
Defines input sources and transformations.
Manages execution and failure recovery.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 10)
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
word_counts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
word_counts.pprint()
ssc.start()
ssc.awaitTermination()Workers and Executors: Processing the Data
How Processing Works
Workers run executors, which process micro-batches.
Spark splits data across executors for parallel execution.
Parallel Processing Example
word_counts.foreachRDD(lambda rdd: rdd.foreachPartition(lambda partition: process_data(partition)))Fault Tolerance in Spark Streaming
Mechanisms for Fault Tolerance
Checkpointing: Saves streaming state periodically.
Data Replication: Replicates data to prevent loss.
Write-Ahead Logs (WAL): Logs incoming data before processing.
ssc.checkpoint("hdfs://path/to/checkpoint")Handling Failures and Data Loss
If a node fails, replicated data ensures recovery.
Write-ahead logs store unprocessed data, ensuring it can be reprocessed.
FAQ
How does Spark Streaming handle the micro-batching of data?
Spark Streaming handles data streams by dividing them into small, fixed-size batches known as micro-batches. These batches are processed using Spark's parallel processing framework. Each micro-batch is treated like a regular RDD (Resilient Distributed Dataset), and transformations such as map, filter, or reduce are applied on each micro-batch. The frequency of micro-batching (e.g., every 1 second, 10 seconds) is controlled by the batch interval parameter. The smaller the batch, the lower the latency, but with potential overhead in processing.
How does Spark Streaming differ from traditional batch processing?
Traditional batch processing handles large chunks of data collected over a period of time (e.g., daily or hourly). In contrast, Spark Streaming processes data in real-time or near-real-time by breaking the incoming data stream into micro-batches. This allows for continuous data processing, which is essential for applications like fraud detection or real-time dashboards. While batch processing can handle large volumes of data effectively, it introduces latency, whereas Spark Streaming reduces that latency but may have overhead due to frequent processing of micro-batches.
What is the role of DStreams in Spark Streaming?
DStreams (Discretized Streams) represent the core abstraction in Spark Streaming. They allow the representation of continuous data streams as sequences of micro-batches. Each DStream is a sequence of RDDs, where each RDD corresponds to data within a specific time window.
Transformations (such as map, reduce, filter) can be applied to DStreams, just like on RDDs, but the transformations operate on each micro-batch independently. DStreams simplify stream processing by treating incoming data as a series of discrete RDDs that can be manipulated using standard Spark operations.
How does the choice of batch duration impact Spark Streaming performance?
The batch duration determines how frequently micro-batches are generated and processed. A shorter batch duration (e.g., 1 second) can result in lower latency, meaning data is processed more quickly. However, it may also lead to higher overhead due to more frequent processing.
On the other hand, a longer batch duration (e.g., 10 seconds) might reduce overhead but increase latency. The key is to strike a balance: too short a batch duration increases processing costs, while too long may result in undesirable delays in real-time processing.
What factors influence the scalability of a Spark Streaming application?
The scalability of a Spark Streaming application is influenced by several factors:
Batch duration: Shorter batches increase processing overhead, while longer batches reduce the need for frequent scheduling but may increase latency.
Data volume: Larger volumes of data require more resources for processing, which can impact performance and scalability.
Cluster size: The number of worker nodes and the resources allocated to them (CPU, memory) will affect how well the application scales.
Parallelism: Spark's ability to parallelize tasks across multiple executors helps improve scalability by distributing the work across the cluster efficiently.
External system integration: The capacity to handle large data ingestion and interaction with other systems (like Kafka, HDFS) also impacts scalability.
How does real-time analytics in Spark Streaming differ from batch-based BI tools?
Real-time analytics in Spark Streaming allows for processing data as it arrives, enabling businesses to take immediate action based on live data. For example, a real-time dashboard can update sales data or fraud detection models immediately as new transactions occur.
On the other hand, batch-based BI tools process data in large chunks at scheduled intervals (e.g., daily, weekly). While batch-based tools can handle large datasets and complex queries efficiently, they suffer from high latency and can't provide real-time insights or quick responses.
What challenges arise when integrating Spark Streaming with external systems?
Integrating Spark Streaming with external systems introduces several challenges:
Data ingestion: Ensuring continuous, real-time data ingestion from external sources (like Kafka, HDFS, or sockets) can be challenging, especially with unreliable or slow sources.
Latency: Managing the latency between receiving data from external sources and processing it in Spark Streaming requires careful tuning of batch duration and other parameters.
Data consistency: Spark Streaming must ensure that data processed across multiple micro-batches is consistent, especially when data sources are not guaranteed to provide data in order or with precise timestamps.
Error handling: External system failures (e.g., Kafka downtime or network issues) may cause data loss or delayed processing. Ensuring fault tolerance and recovery mechanisms is crucial.
How does Spark Streaming ensure data reliability in case of failures?
Spark Streaming ensures data reliability through the following mechanisms:
Checkpointing: Spark periodically saves the state of the DStreams (e.g., processed data and offsets). In case of failure, the system can recover from the last checkpointed state.
Data replication: Spark replicates RDDs across multiple nodes to prevent data loss. If a worker node fails, another replica of the data can be used to continue processing.
Write-Ahead Logs: Before processing data, it is written to a write-ahead log (WAL), which ensures that data is not lost even if the driver fails. This log acts as a backup, and the data can be replayed when the driver recovers.
Fault tolerance at the DStream level: If a failure occurs during processing, Spark can retry operations on failed micro-batches using the checkpoint or replication data.
