

Spark Streaming's architecture represents a powerful framework for processing real-time data.
Understanding the Micro-Batch Architecture: How Spark Streaming Works
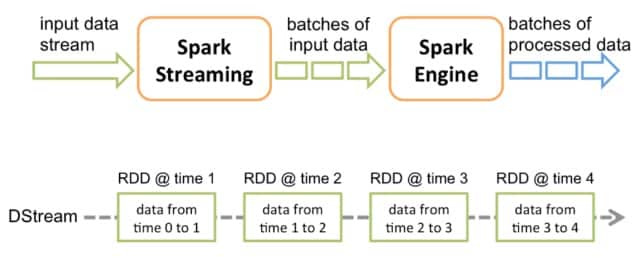
Spark Streaming processes data in small, time-bounded chunks called micro-batches rather than processing each record individually as it arrives. These micro-batches are typically measured in seconds (1-5 seconds is common) and allow Spark to achieve high throughput while maintaining reasonable latency.
Think of the micro-batch architecture like a WWE Royal Rumble match. In a Royal Rumble, wrestlers enter the ring at fixed intervals (like data being collected into micro-batches), and then all wrestlers currently in the ring battle simultaneously (batch processing). This approach balances continuous action with manageable chaos - exactly what Spark Streaming does with data.
Here's a simple example of how to initialize a Spark Streaming context with a 2-second batch interval:
```python
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a Spark context
sc = SparkContext("local[2]", "StreamingExample")
# Create a Streaming context with 2-second batch interval
ssc = StreamingContext(sc, 2)
# Start the streaming context
ssc.start()
ssc.awaitTermination()
```Batch vs. Stream Processing Architectures: A Comparative Look
Traditional batch processing handles large volumes of data at once, processing entire datasets in scheduled jobs. Stream processing, on the other hand, handles data continuously as it arrives, enabling real-time analysis and insights.
In WWE terms, batch processing is like a pre-recorded WWE pay-per-view event - it's produced, edited, and delivered as a complete package. Streaming processing is more like WWE Monday Night Raw going out live - events happen in real-time, and reactions are immediate.
Here's a quick comparison of batch vs. streaming code approaches:
```python
# Batch processing example
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("BatchExample").getOrCreate()
batch_data = spark.read.csv("hdfs://data/daily_logs.csv")
results = batch_data.groupBy("user_id").count()
results.write.save("hdfs://results/daily_counts")
# Streaming equivalent
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 1) # 1-second batches
stream_data = ssc.socketTextStream("localhost", 9999)
parsed_data = stream_data.map(lambda line: line.split(","))
user_counts = parsed_data.map(lambda x: (x[0], 1)).reduceByKey(lambda a, b: a + b)
user_counts.pprint()
```Discretized Streams (DStreams): The Foundation of Spark Streaming
DStreams (Discretized Streams) are the fundamental abstraction in Spark Streaming. A DStream represents a continuous sequence of RDDs (Resilient Distributed Datasets), with each RDD containing data from a specific time interval. This abstraction allows developers to apply transformations and actions as they would with regular RDDs.
In WWE terms, think of DStreams as a wrestler's career timeline. Each individual match (RDD) is a discrete event, but together they form a continuous narrative (the DStream). Just as a wrestler builds their career through a series of matches, a DStream builds its processing through a series of RDDs.
Here's an example showing basic DStream operations:
```python
# Create a DStream from a socket source
lines = ssc.socketTextStream("localhost", 9999)
# Apply transformations
words = lines.flatMap(lambda line: line.split(" "))
word_pairs = words.map(lambda word: (word, 1))
word_counts = word_pairs.reduceByKey(lambda x, y: x + y)
# Output the results
word_counts.pprint()
```Each transformation in this code creates a new DStream derived from the original, similar to how a wrestler might evolve their character through different storylines while maintaining their core identity.
The Driver Program: Orchestrating the Streaming Application
The Driver Program is the central coordinator of a Spark Streaming application. It runs the main function, creates the StreamingContext, defines the processing logic, and manages the execution across the cluster. The Driver is responsible for dividing the streaming computation into micro-batches and scheduling them as Spark jobs.
In WWE terms, the Driver is Vince McMahon – the boss who calls the shots, schedules the matches, and orchestrates the entire show. Just as Vince decides which wrestlers go into which matches and storylines, the Driver decides how data will be processed and which executors will handle specific tasks.
Here's a code snippet illustrating how a Driver program sets up and controls a Spark Streaming application:
```python
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
# Driver program configuration
conf = SparkConf().setAppName("StreamingApp").setMaster("yarn")
conf.set("spark.executor.memory", "2g")
conf.set("spark.streaming.backpressure.enabled", "true")
# Create context with Driver controlling the batch interval
ssc = StreamingContext(conf, batchDuration=5)
# Define the processing logic
lines = ssc.textFileStream("hdfs://logs/")
error_lines = lines.filter(lambda line: "ERROR" in line)
error_counts = error_lines.countByWindow(windowDuration=60, slideDuration=10)
error_counts.pprint()
# Driver controls the application lifecycle
ssc.start()
ssc.awaitTermination()
```In this example, the Driver program defines the streaming source, processing logic, and execution parameters, much like how WWE's creative team plans out matches and storylines.
Workers and Executors: Processing the Data
Workers and Executors form the distributed processing layer in Spark Streaming. Workers are nodes in the cluster that host Executors, while Executors are JVM processes that run tasks. Each Executor is capable of running multiple tasks in parallel, with each task processing a partition of the data.
In WWE terms, if the Driver is Vince McMahon, then the Workers are the arenas where shows take place, and the Executors are the actual wrestlers who perform the matches. Just as multiple wrestlers can perform simultaneously in different rings or segments, multiple Executors can process different partitions of your data in parallel.
Here's how you might configure workers and executors in a PySpark application:
```python
# Setting executor and worker configuration
conf = SparkConf().setAppName("StreamingExample")
conf.set("spark.executor.instances", "10") # Number of executors
conf.set("spark.executor.cores", "4") # Cores per executor
conf.set("spark.executor.memory", "8g") # Memory per executor
conf.set("spark.driver.memory", "4g") # Driver memory
# Create the context with this configuration
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 2)
```When this application runs, the Driver will coordinate with cluster managers (like YARN) to allocate these resources across the cluster, similar to how WWE production teams coordinate with venues to set up multiple rings and staging areas.
Fault Tolerance in the Architecture: Ensuring Reliability
Fault tolerance is a critical aspect of Spark Streaming architecture. It ensures that your streaming application can recover from failures and continue processing without data loss. This is achieved through a combination of RDD lineage, checkpointing, and write-ahead logs (WAL).
RDD Lineage: Each RDD in a DStream maintains a lineage, which is a record of the transformations that were applied to it. If an RDD is lost, Spark can reconstruct it by replaying the lineage. This is like a wrestler's training regimen, allowing them to recover from a setback.
Checkpointing: Spark Streaming can checkpoint the state of the application to a reliable storage system. This allows the application to recover from failures without losing all its progress. This is like a wrestler having a backup plan, ensuring they can get back in the game even after a major blow.
Enabling checkpointing
ssc.checkpoint("checkpoint_directory")
Checkpointing ensures that if the driver program fails, it can recover its state from the checkpoint directory.
In WWE terms, fault tolerance is like having backup plans for when a wrestler gets injured mid-storyline. Just as WWE might rewrite scripts or substitute performers to ensure the show goes on, Spark Streaming has mechanisms to recover from node failures or application crashes.
Here's how to implement checkpointing for fault tolerance:
```python
from pyspark.streaming import StreamingContext
from pyspark import SparkContext
# Function to create StreamingContext
def create_context():
sc = SparkContext("yarn", "FaultTolerantApp")
ssc = StreamingContext(sc, 10) # 10-second batch interval
# Set up your streaming computation
lines = ssc.socketTextStream("localhost", 9999)
word_counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
word_counts.pprint()
# Set the checkpoint directory
ssc.checkpoint("hdfs:///checkpoint")
return ssc
# Get or create a StreamingContext
ssc = StreamingContext.getOrCreate("hdfs:///checkpoint", create_context)
# Start the computation
ssc.start()
ssc.awaitTermination()
```The checkpointing mechanism periodically saves the application's state to a reliable storage system (like HDFS). If the application crashes, it can recover by loading the most recent checkpoint and continuing from there. This is similar to how WWE might replay video packages to remind viewers of storylines after a wrestler returns from injury.
Spark Streaming also uses write-ahead logs to record received data before processing. If a failure occurs during processing, this ensures no data is lost - much like how WWE films backup angles during live events in case the planned shot doesn't work out.
Putting It All Together
Spark Streaming's architecture combines these elements into a cohesive system. The Driver orchestrates the application, creating DStreams that process data in micro-batches. Workers and Executors handle the distributed processing, while fault tolerance mechanisms ensure reliability.
Just as WWE seamlessly combines individual wrestlers, storylines, and matches into an entertaining show, Spark Streaming integrates these architectural components to create a powerful, real-time data processing framework. And just like how WWE adapts to unexpected circumstances during a live show, Spark Streaming's architecture is designed to be resilient and adaptable in the face of failures or changing data patterns.
By understanding this architecture, you'll be better equipped to design, implement, and troubleshoot your Spark Streaming applications - becoming the undisputed champion of real-time data processing.
