

We will talk in detail of Spark's execution process, its optimization frameworks (Catalyst Optimizer and Adaptive Query Execution), and its low-level execution engine (Tungsten)
Steps in Spark Execution
Spark’s execution process is divided into multiple steps, starting from application submission to final resource release.
Step-by-Step Explanation

1. Application Submission
The user submits a Spark application to the cluster manager (e.g., YARN, Kubernetes). This application contains transformations (`map`, `filter`) and actions (`count`, `collect`) that define how distributed datasets will be processed.
Booking a wrestling event where the promoter (user) submits match details (application) to WWE management (cluster manager).
2. Driver Program Launch
The driver program initializes and manages the lifecycle of the Spark application. It constructs logical and physical execution plans, schedules tasks, and monitors their progress.
Vince McMahon orchestrating the entire event, ensuring wrestlers know their roles and overseeing the matches.
3. Resource Allocation
The cluster manager allocates resources (executors) based on the application's requirements. Executors are assigned to worker nodes where they perform tasks in parallel.
WWE management assigns wrestlers (executors) to different arenas (worker nodes) based on their skills and availability.
4. Executor Launch
Executors are launched on worker nodes to execute tasks, manage intermediate data, and report progress back to the driver program.
Wrestlers step into the ring, ready to perform their moves and contribute to the storyline.
5. Logical Execution Plan Creation
The driver constructs a logical plan based on user-defined transformations and actions. This plan represents high-level operations such as `map`, `filter`, and `join`.
Planning high-level storylines for each match—moves like `map` or `filter` are choreographed for maximum drama.
6. Physical Execution Plan Creation
The Catalyst Optimizer transforms the logical plan into an optimized physical plan by applying rules and cost-based optimizations.
Coaches choreograph detailed sequences of moves (physical strategies like joins), ensuring efficiency in execution.
7. Stage and Task Scheduling
The physical plan is divided into stages based on data dependencies (narrow or wide). Tasks within each stage are scheduled for execution across available executors.
Dividing matches into rounds—each round has its lineup of wrestlers performing simultaneously in different parts of the arena.
8. Task Initialization
Executors initialize tasks by deserializing metadata received from the driver program. This includes instructions about which data partitions to process and what operations to perform.
Wrestlers review their move list before stepping into the ring.
9. Data Acquisition
Input data is fetched from storage systems like HDFS, S3, or local disk partitions. Executors load this data into memory for processing.
Gathering props or equipment needed for performance before entering the ring.
10. Task Execution
Tasks perform computations as specified in the physical plan, applying transformations (`map`, `filter`) and aggregations (`reduceByKey`).
Wrestlers step into the ring and execute their moves—slams, holds, finishers—as choreographed by their coach.
11. Intermediate Data Storage
Intermediate results may be cached or stored temporarily in memory or disk for use in subsequent stages of execution.
Storing highlight reels between rounds or matches until they can be used later.
12. Shuffle Data Handling
Data is shuffled between executors when wide dependencies (e.g., joins or groupBy) require it. This involves sorting data and transferring it across partitions so related rows end up together.
Tag-team wrestling where wrestlers exchange tags mid-match to keep up with opponents.
13. Task Completion and Result Reporting
Completed tasks report results back to the driver program, which tracks statuses and resubmits failed tasks if necessary.
Wrestlers report back with results after each match, triggering backup plans if needed.
14. Task Garbage Collection
Once tasks complete successfully, intermediate data stored in memory or disk is cleared to free up resources for subsequent tasks.
Clearing props from one match before setting up for the next one—ensuring smooth transitions between performances.
15. Awaiting New Tasks
Executors wait for new instructions from the driver program after completing their current set of tasks.
Wrestlers rest backstage while awaiting instructions for their next match.
16. Application Termination and Resource Release
Once all tasks are completed successfully, resources allocated by the cluster manager are released back into the pool for other applications.
Wrapping up matches—wrestlers leave the arena, resources are freed up, fans receive final results.
How Catalyst Optimizer, AQE, and Tungsten Help in Spark Execution
The execution flow in Spark involves multiple stages where Catalyst Optimizer, Adaptive Query Execution (AQE), and Tungsten play critical roles. Each component contributes to optimizing and executing queries efficiently at different stages of the process.
Catalyst Optimizer: Query Optimization Framework
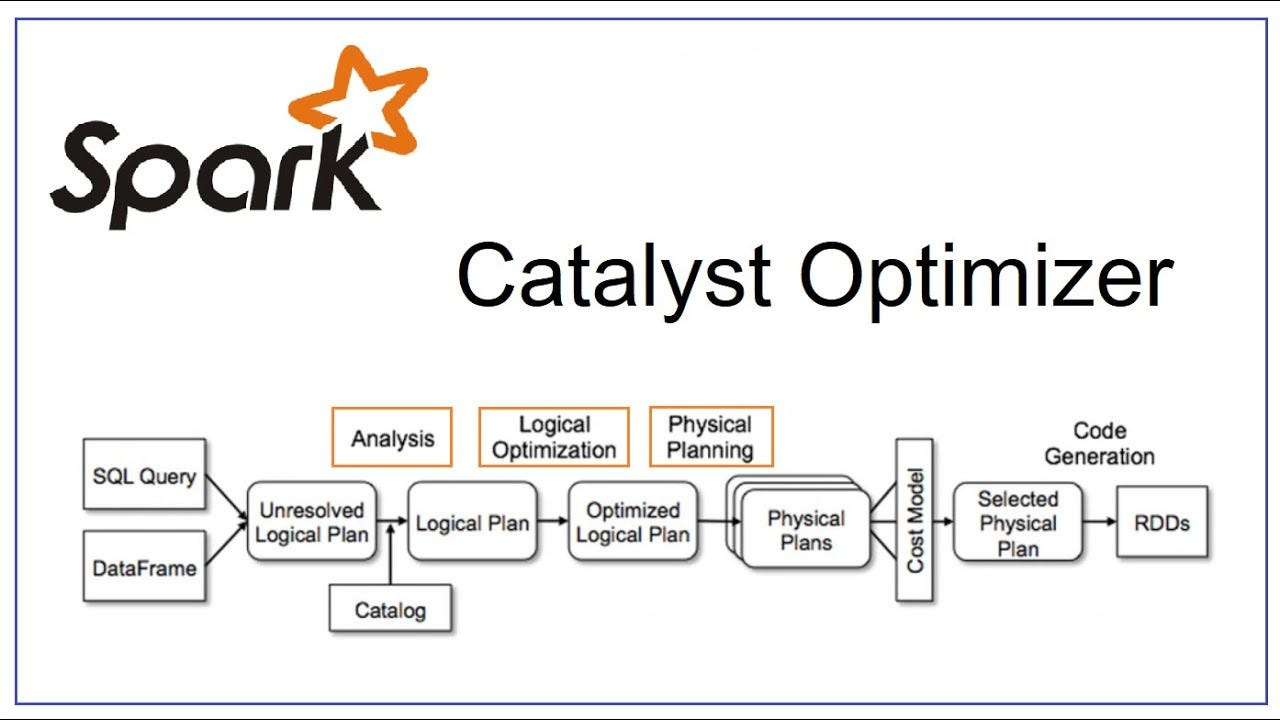
Where It Helps in Spark Execution:
Catalyst operates during the Logical Execution Plan Creation and Physical Execution Plan Creation stages. It transforms user queries into efficient execution plans by applying rule-based and cost-based optimizations.
1. Logical Optimization:
- Simplifies the logical plan by applying techniques like:
- Predicate Pushdown: Moves filters closer to the data source to reduce unnecessary processing.
- Constant Folding: Precomputes constant expressions at compile time.
- Projection Pruning: Removes unused columns to minimize data movement.
- Impact: Reduces the size of intermediate datasets early in the pipeline.
2. Cost-Based Optimization (CBO):
- Uses table statistics (e.g., row counts, column cardinality) to evaluate resource costs and select the most efficient physical plan.
- Example: Chooses between broadcast join or sort-merge join based on dataset sizes.
- Impact: Ensures resource-efficient operations.
3. Physical Plan Generation:
- Converts the logical plan into one or more physical plans using strategies like:
- Broadcast Join
- Sort-Merge Join
- Shuffle Hash Join
- Evaluates candidate plans using a cost model and selects the best one.
- Impact: Produces an initial physical plan that balances performance and resource usage.
4. Code Generation:
- Works with Tungsten to generate optimized JVM bytecode for operations like filtering, joins, and aggregations.
- Impact: Reduces runtime overhead by creating highly efficient machine code.
Adaptive Query Execution (AQE): Runtime Query Optimization
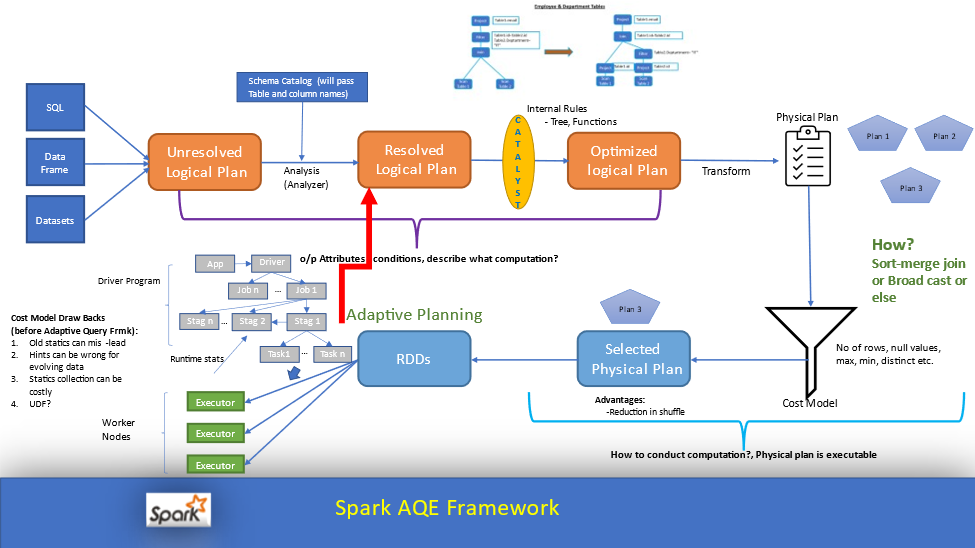
Where It Helps in Spark Execution:
AQE operates during the Stage and Task Scheduling phase, dynamically refining the initial physical plan created by Catalyst based on actual data characteristics observed at runtime.
1. Dynamic Join Strategy Switching:
- Adjusts join strategies (e.g., switching from sort-merge join to broadcast join) based on observed dataset sizes during execution.
- Impact: Reduces shuffle costs and improves query performance.
2. Dynamic Partition Coalescing:
- Merges small shuffle partitions into larger ones at runtime to reduce task overhead and improve parallelism.
- Example: If many small partitions are created after a shuffle, AQE combines them to avoid excessive small tasks.
- Impact: Improves resource utilization and reduces task scheduling overhead.
3. Skew Join Optimization:
- Detects skewed partitions (e.g., one partition is much larger than others) using shuffle statistics and splits them into smaller subpartitions for balanced processing across executors.
- Impact: Prevents bottlenecks caused by uneven data distribution.
4. Dynamic Partition Pruning:
- Eliminates unnecessary partitions dynamically during runtime when filter conditions are resolved late (e.g., in `WHERE` clauses with subqueries).
- Example: If only certain partitions are needed after evaluating a filter, AQE prunes irrelevant ones.
- Impact: Reduces data processing overhead significantly.
Tungsten Engine: Low-Level Execution Framework
Where It Helps in Spark Execution:
Tungsten operates during the Task Execution phase, providing low-level optimizations for memory management, CPU efficiency, and data processing.
1. Memory Management:
- Uses off-heap memory with binary formats to reduce garbage collection overhead.
- Example: Stores intermediate results in compact binary formats (`UnsafeRow`) for faster access.
- Impact: Improves memory efficiency and reduces JVM-related overhead.
2. Whole-Stage Code Generation:
- Dynamically generates optimized JVM bytecode for entire query stages using techniques like loop unrolling and SIMD (Single Instruction Multiple Data) instructions.
- Example: Instead of interpreting each operation separately, Tungsten compiles them into a single optimized block of code.
- Impact: Minimizes CPU cycles required for execution.
3. Vectorized Processing:
- Processes data in batches rather than row-by-row, leveraging modern CPU architectures for faster computation.
- Example: Aggregations or joins are performed on batches of rows simultaneously rather than one row at a time.
- Impact: Significantly speeds up computation-heavy operations.
4. Integration with Catalyst and AQE:
- Executes physical plans generated by Catalyst or refined by AQE efficiently at runtime.
- Example: If AQE switches a join strategy to broadcast join, Tungsten ensures that this new plan is executed with minimal overhead.
- Impact: Provides the foundation for executing optimized plans effectively.
Some points to ponder over
What techniques does the Catalyst Optimizer use for logical optimization?
- Predicate Pushdown
- Constant Folding
- Projection Pruning
- Rule-Based Rewriting
How does the Catalyst Optimizer decide the order of execution for multi-join queries?
- Uses rule-based reordering initially to simplify joins.
- Applies cost-based optimization if statistics are available to evaluate alternative join orders based on estimated costs.
How does the Catalyst Optimizer optimize filter clauses?
- Pushes filters closer to the data source (predicate pushdown).
- Precomputes constant expressions at compile time (constant folding).
- Combines redundant filters for efficiency (filter rewriting).
How does the Catalyst Optimizer generate physical plans?
- Maps logical operators to physical operators using predefined strategies (e.g., broadcast join vs sort-merge join).
- Generates multiple candidate plans and evaluates them using a cost model.
- Selects the most efficient plan based on estimated resource usage.
How does the Catalyst Optimizer handle data partitioning in physical plans?
- Preserves existing partitioning schemes when possible.
- Introduces shuffle exchanges only when necessary for operations like joins or aggregations.
- Evaluates partitioning costs during physical planning.
How does the Catalyst Optimizer minimize shuffle operations?
- Preserves existing partitioning schemes whenever possible.
- Pushes filters early to reduce data volume before shuffling (predicate pushdown).
- Chooses efficient join strategies (e.g., broadcast joins) that avoid unnecessary shuffles.
Catalyst Optimizer, AQE, Tungsten engine and Photon engine in Nutshell.
In standard Spark environments:
Catalyst generates a logical plan → initial physical plan → passes it to AQE.
AQE refines this plan dynamically at runtime → submits it to Tungsten for execution.
AQE dynamically adjusts query plans at runtime but relies on
Tungsten for efficient low-level execution of those plans through optimized memory management, code generation, and vectorized processing.
In Databricks environments:
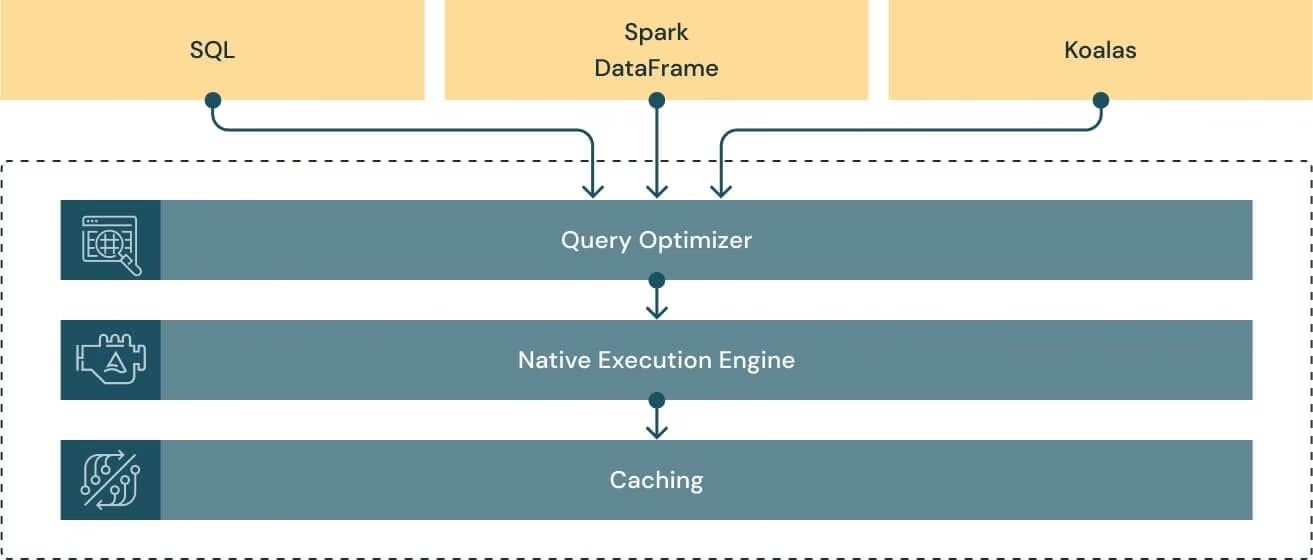
Photon replaces Tungsten as the low-level execution engine after AQE refines the physical plan.
