

As Part 2 of this Blog series on Joins & Optimizing them in Apache Spark, we will be discussing more about these topics:
- Data Skewness
- Join Hints
- Filter Pushdown
- Column Pruning
- Predicate Pushdown
- Using Join Conditions with Complex Data Types
- Optimizing Joins with Window Functions
- Join Performance with Caching
- Adaptive Query Execution (AQE)
Data Skewness
Data skew happens when certain values of your join key appear much more often than others. This can overload some executors while others sit idle, leading to slow joins. Imagine a room where everyone wants to talk to the same one or two people—it creates a bottleneck.
Real-world example
You're joining customer orders with customer information, but a few very frequent customers (e.g., wholesale buyers) cause skew on the customer_id join key.
Standard Approach (Skewed Join)
```python
orders = spark.read.csv("orders.csv", header=True, inferSchema=True)
customers = spark.read.csv("customers.csv", header=True, inferSchema=True)
orders.join(customers, "customer_id", "inner").show()
```Efficient Approach (Handling Skew)
- Salting: Add a random value to the join key of the skewed records to distribute them across partitions.
- Broadcast Join: If the smaller table has the skewed keys, broadcast it to avoid shuffling the larger table.
- Isolate and Repartition: Separate the skewed keys, repartition them, and join them separately.
```python
from pyspark.sql.functions import rand
# Example of salting (simplified)
orders = orders.withColumn("salted_customer_id", col("customer_id") * 10000 + rand())
customers = customers.withColumn("salted_customer_id", col("customer_id") * 10000 + rand())
orders.join(customers, "salted_customer_id", "inner").show()
```Handling skew often requires a combination of techniques and careful analysis of your data.
Join Hints
Join hints are like gentle suggestions to Spark's optimizer about how to perform a join. While Spark is usually good at choosing the best strategy, hints can sometimes help in specific situations where you have deeper knowledge of your data.
Real-world example
You know that a broadcast hash join would be ideal for a specific join, but Spark's optimizer isn't choosing it automatically.
Standard Approach (No Hints)
```python
table_a = spark.read.csv("table_a.csv", header=True, inferSchema=True)
table_b = spark.read.csv("table_b.csv", header=True, inferSchema=True)
table_a.join(table_b, "join_key", "inner").show()
```Efficient Approach (Using Hints)
```python
table_a.join(table_b, "join_key", "inner", hint="broadcast").show()
```Here, hint="broadcast" encourages Spark to use a broadcast hash join. Other hints include merge, shuffle_hash, and shuffle_replicate_nl.
Note:
- Use hints sparingly and only when you have a good reason.
- Incorrect hints can actually degrade performance.
- Spark might ignore hints if it determines a better strategy.
Filter Pushdown
This optimization pushes filtering operations closer to the data source. Instead of reading all the data and then filtering, Spark tries to apply the filter at the source itself (e.g., within a database or file format like Parquet). This reduces the amount of data that needs to be processed. It's like searching for a specific item in a catalog before going to the store—you save a trip.
Real-world example
You have a large dataset of sales records (sales) stored in Parquet format, and you want to analyze sales for a specific month.
Standard Approach (Filtering after reading)
```python
sales = spark.read.parquet("sales.parquet")
sales.filter(col("month") == "January").show()
```Efficient Approach (Filter Pushdown)
```python
sales = spark.read.parquet("sales.parquet").filter(col("month") == "January")
sales.show()
```In the efficient approach, Spark will push the filter operation down to the Parquet reader, so it only reads the relevant data for January.
- Filter pushdown works best with file formats that support it, like Parquet and ORC.
- The complexity of the filter can affect whether it can be pushed down.
Column Pruning
Similar to filter pushdown, column pruning avoids reading unnecessary columns. If your query only needs a few columns from a table, Spark will try to read only those columns from the data source. This reduces I/O and speeds up processing. Think of it like ordering à la carte instead of the full buffet—you only get what you need.
Real-world example
You have a wide table of customer data (customers) with many columns, but you only need the customer_id and email for your analysis.
Standard Approach (Reading all columns)
```python
customers = spark.read.csv("customers.csv", header=True, inferSchema=True)
customers.select("customer_id", "email").show()
```Efficient Approach (Column Pruning)
```python
customers = spark.read.csv("customers.csv", header=True, inferSchema=True).select("customer_id", "email")
customers.show()
```By selecting the columns you need during the read operation, Spark will prune the unnecessary columns and read only customer_id and email from the source.
- Column pruning is most effective with columnar file formats like Parquet and ORC.
- The query's structure can influence whether column pruning is applied.
Predicate Pushdown
Predicate pushdown is a more general form of filter pushdown. It applies not just to simple filters, but also to more complex conditions in your WHERE clause, including those involving joins. Spark tries to push these predicates as close to the data source as possible to reduce the amount of data processed. Think of it as giving the store a detailed shopping list with specific criteria (like "organic, non-GMO tomatoes under $2/lb") so they can pre-select the items for you.
Real-world example
You have two tables, orders and customers, and you want to find orders from "gold" customers placed in the last month.
Standard Approach (Filtering after join)
```python
orders = spark.read.csv("orders.csv", header=True, inferSchema=True)
customers = spark.read.csv("customers.csv", header=True, inferSchema=True)
orders.join(customers, "customer_id", "inner") \.filter((col("customer_tier") == "gold") & (col("order_date") >= "2024-11-01")) \.show()
```Efficient Approach (Predicate Pushdown)
If your data source supports it, Spark might be able to push down both the join condition (customer_id) and the filters (customer_tier and order_date) to the source, significantly reducing the amount of data read and processed.
The pushdown happens automatically if the data source supports it.
```python
orders = spark.read.csv("orders.csv", header=True, inferSchema=True)
customers = spark.read.csv("customers.csv", header=True, inferSchema=True)
orders.join(customers, "customer_id", "inner") \.filter((col("customer_tier") == "gold") & (col("order_date") >= "2024-11-01")) \.show()
```- The effectiveness of predicate pushdown depends on the capabilities of the data source (e.g., database, file format).
- Complex predicates might not always be fully pushed down.
Using Join Conditions with Complex Data Types
Spark can handle joins on columns with complex data types like arrays, structs, and maps. However, these joins can be less efficient than joins on simple data types. Optimization techniques might involve:
- Exploding or flattening: Transforming complex types into simpler ones before the join.
- UDFs (User-Defined Functions): Creating custom functions to compare complex types if Spark's built-in functions aren't sufficient.
Real-world example
You have a table of user profiles (user_profiles) where one column (interests) is an array of strings representing user interests. You want to join this with a table of products (products) that also has an interests array, to recommend products to users.
Standard Approach (Joining on array columns)
```python
user_profiles = spark.read.json("user_profiles.json")products = spark.read.json("products.json")
# This might be inefficient depending on the array size and complexity
user_profiles.join(products, array_contains(user_profiles.interests, products.interests)).show()
```Efficient Approach (Exploding arrays)
```python
from pyspark.sql.functions import explode
user_profiles = user_profiles.select(explode("interests").alias("interest"), "*")
products = products.select(explode("interests").alias("interest"), "*")
# Now join on the exploded 'interest' column
user_profiles.join(products, "interest").show()
```- The best approach depends on the specific complex data type and the join condition.
- Consider the performance implications of exploding or flattening complex types, as it can increase the size of the data.
Optimizing Joins with Window Functions
Window functions operate on a set of rows (a "window") related to the current row. They can sometimes replace self-joins, which can be less efficient. Instead of joining a table to itself, a window function can calculate aggregates or rankings within partitions of the data. Imagine trying to find the tallest person in each group—a window function can do this without a self-join.
Real-world example
You have a table of employee salaries (salaries) and want to find the highest salary in each department.
Standard Approach (Self-Join)
```python
from pyspark.sql.functions import max
salaries = spark.read.csv("salaries.csv", header=True, inferSchema=True)
# Calculate max salary per department
max_salaries = salaries.groupBy("department").agg(max("salary").alias("max_salary"))
# Join back to the original table
salaries.join(max_salaries, "department", "inner") \.filter(salaries.salary == max_salaries.max_salary) \.show()
```Efficient Approach (Window Function)
```python
from pyspark.sql.window import Window
window_spec = Window.partitionBy("department")
salaries.withColumn("max_salary", max("salary").over(window_spec)) \.filter(col("salary") == col("max_salary")) \.show()
```The window function calculates the max_salary for each department without a self-join.
- Window functions can be more concise and efficient than self-joins in many cases.
- Consider the complexity of the window function and the size of the data when deciding if it's the best approach.
Join Performance with Caching
Caching can significantly improve join performance by storing frequently used data in memory. When Spark needs to access the same data again, it can retrieve it from memory instead of reading it from disk. This is especially helpful for joins involving smaller tables or intermediate results that are reused multiple times. Think of it like keeping your most-used cooking ingredients within easy reach on the counter instead of in the pantry.
Real-world example
You have a dimension table (products) that's used in multiple joins throughout your application.
Standard Approach (No caching)
```python
products = spark.read.csv("products.csv", header=True, inferSchema=True)
# ... multiple joins using 'products' ...
```Efficient Approach (Caching)
```python
products = spark.read.csv("products.csv", header=True, inferSchema=True).cache()
# ... multiple joins using 'products' ...
```By calling cache(), you instruct Spark to store products in memory. Subsequent joins using products will be much faster.
- Choose the right storage level for your cached data (e.g., MEMORY_ONLY, MEMORY_AND_DISK).
- Be mindful of memory limitations—caching too much data can lead to spills to disk or even out-of-memory errors.
- Unpersist cached data when you're done with it to free up memory.
Adaptive Query Execution (AQE)
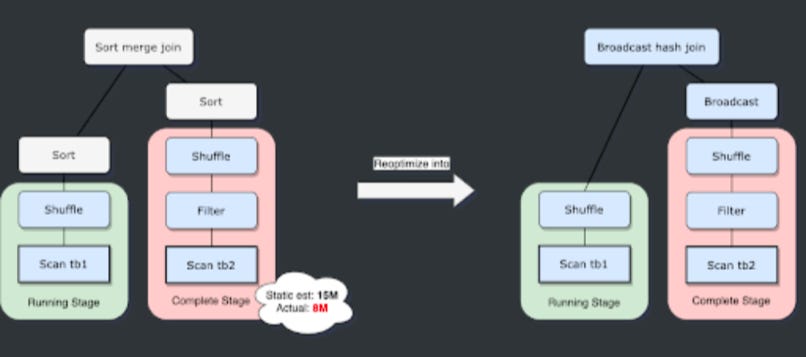
AQE is like having a smart autopilot for your Spark queries. It allows Spark to adjust the query execution plan during runtime based on what it learns about the data. This can lead to significant performance improvements, especially for complex queries with joins. Imagine a GPS that reroutes you in real-time to avoid traffic jams—AQE does something similar for your Spark jobs.
Real-world example
You have a query with multiple joins, and the initial plan chosen by Spark might not be the most efficient due to data skew or inaccurate estimations.
Efficient Approach (AQE)
AQE is enabled by default in Spark 3.2 and later. You don't need to change your code, but you can tune AQE settings if needed. AQE will automatically optimize the query execution plan during runtime
AQE can perform optimizations like:
- Coalescing shuffle partitions: Merging small partitions after a shuffle to reduce overhead.
- Switching join strategies: Changing from a sort-merge join to a broadcast hash join if the data size allows.
- Optimizing skew joins: Handling data skew dynamically during the join.
Note:
- AQE is a powerful tool for optimizing complex queries.
- You can control AQE behavior with configuration settings like spark.sql.adaptive.enabled and spark.sql.adaptive.skewJoin.enabled.
